1 Linux 安装 Kafka
1.1 安装前的环境准备
由于 Kafka 是用 Scala 语言开发的,运行在 JVM 上,因此在安装Kafka之前需要先安装JDK。
yum install java-1.8.0-openjdk* -ykafka 依赖 zookeeper,所以需要先安装 zookeeper。
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.5.8/apache-zookeeper-3.5.8-bin.tar.gz解压归档包。
tar -zxvf apache-zookeeper-3.5.8-bin.tar.gz cd apache-zookeeper-3.5.8-bin复制配置文件。
cd apache-zookeeper-3.5.8-bin
cp conf/zoo_sample.cfg conf/zoo.cfg启动 zookeeper Server。
cd apache-zookeeper-3.5.8-bin
bin/zkServer.sh start启动客户端 zookeeper Client。
cd apache-zookeeper-3.5.8-bin
bin/zkCli.sh查看zk的根目录相关节点
ls / 1.2 Kafka 安装
1.2.1 下载安装包
下载2.4.1 release版本,并解压:
wget https://archive.apache.org/dist/kafka/2.4.1/kafka_2.11-2.4.1.tgz2.11是scala的版本,2.4.1是kafka的版本。
解压归档包。
tar -xzf kafka_2.11-2.4.1.tgz1.2.2 修改配置
cd kafka_2.11-2.4.1
#修改配置文件
vim config/server.properties修改如下配置内容。
#broker.id属性在kafka集群中必须要是唯一
broker.id=0
#kafka部署的机器ip和提供服务的端口号
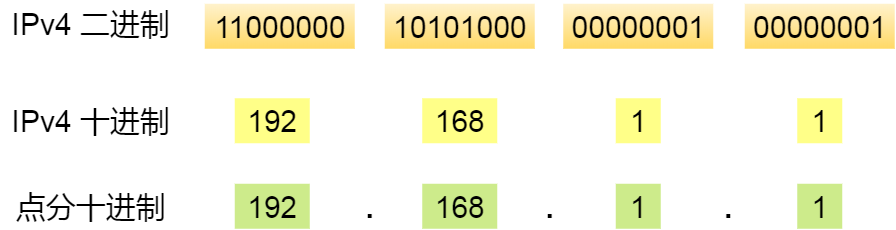
listeners=PLAINTEXT:192.168.31.162:9092
#kafka的消息存储文件
log.dir=/usr/local/data/kafka-logs
#kafka连接zookeeper的地址
zookeeper.connect=192.168.31.162:21811.2.2.1 server.properties核心配置
| Property | Default | Description |
| broker.id | 0 | 每个broker都可以用一个唯一的非负整数id进行标识;这个id可以作为broker的“名字”,你可以选择任意你喜欢的数字作为id,只要id是唯一的即可。 |
| log.dirs | /tmp/kafka-logs | kafka存放数据的路径。这个路径并不是唯一的,可以是多个,路径之间只需要使用逗号分隔即可;每当创建新partition时,都会选择在包含最少partitions的路径下进行。 |
| listeners | PLAINTEXT://192.168.31.192:9092 | server接受客户端连接的端口,ip配置kafka本机ip即可。 |
| zookeeper.connect | localhost:2181 | zooKeeper连接字符串的格式为:hostname:port,此处hostname和port分别是ZooKeeper集群中某个节点的host和port;zookeeper如果是集群,连接方式为 hostname1:port1, hostname2:port2, hostname3:port3。 |
| log.retention.hours | 168 | 每个日志文件删除之前保存的时间。默认数据保存时间对所有topic都一样。 |
| num.partitions | 1 | 创建topic的默认分区数 |
| default.replication.factor | 1 | 自动创建topic的默认副本数量,建议设置为大于等于2 |
| min.insync.replicas | 1 | 当producer设置acks为-1时,min.insync.replicas指定replicas的最小数目(必须确认每一个repica的写数据都是成功的),如果这个数目没有达到,producer发送消息会产生异常 |
| delete.topic.enable | false | 是否允许删除主题 |
1.2.3 启动 Kafka 服务
现在来启动kafka服务:启动脚本语法
kafka-server-start.sh [-daemon] server.properties可以看到,server.properties 的配置路径是一个强制的参数,-daemon 表示以后台进程运行,否则ssh客户端退出后,就会停止服务。(注意,在启动kafka时会使用linux主机名关联的ip地址,所以需要把主机名和linux的ip映射配置到本地host里,用vim /etc/hosts)。
启动kafka。
cd kafka_2.11-2.4.1
#后台启动,不会打印日志到控制台
bin/kafka-server-start.sh -daemon config/server.properties
#会在控制台打印日志
bin/kafka-server-start.sh config/server.properties &进入zookeeper目录通过zookeeper客户端查看下zookeeper的目录树。
bin/zkCli.sh
#查看zk的根目录kafka相关节点
ls /
#查看kafka节点
ls /brokers/ids
#停止kafka
bin/kafka-server-stop.sh
2 Docker 安装 Kafka
2.1 安装运行 zookeeper
搜索 zookeeper 镜像。
docker search zookeeper
拉取镜像。
docker pull zookeeper
启动 zookeeper 容器。
docker run -d --name zookeeper -p 2181:2181 zookeeper查看容器。
docker ps
可以看到,zookeeper 容器已经启动。
2.2 安装运行 Kafka
搜索 kafka镜像。
docker search kafka
拉取镜像。
docker pull bitnami/kafka启动 Kafka 容器。
docker run -d --name kafka -p 9092:9092 --link zookeeper:zookeeper \
-v /usr/kafka/config/server.properties:/config/server.properties \
--env KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181 \
--env KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092 \
--env KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \
--env KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR=1 bitnami/kafka 查看容器。
进入 zookeeepr 容器,查看节点信息。
docker exec -it 80bf /bin/bash启动客户端。
bin/zkCli.sh
查看节点状态。

3 Kafka 集群环境
3.1 Linux Kafak集群
对于 kafka 来说,一个单独的 broker 意味着 kafka 集群中只有一个节点。要想增加 kafka 集群中的节点数量,只需要多启动几个 broker 实例即可。为了有更好的理解,现在我们在一台机器上同时启动三个broker实例。
首先,建立好其他 2 个broker的配置文件:
cp config/server.properties config/server-1.properties
cp config/server.properties config/server-2.properties配置文件的需要修改的内容分别如下:
config/server-1.properties:
#broker.id属性在kafka集群中必须要是唯一
broker.id=1
#kafka部署的机器ip和提供服务的端口号
listeners=PLAINTEXT://192.168.31.162:9093
log.dir=/usr/local/data/kafka-logs-1
#kafka连接zookeeper的地址,要把多个kafka实例组成集群,对应连接的zookeeper必须相同
zookeeper.connect=192.168.31.162:2181config/server-2.properties:
#broker.id属性在kafka集群中必须要是唯一
broker.id=2
#kafka部署的机器ip和提供服务的端口号
listeners=PLAINTEXT://192.168.31.162:9093
log.dir=/usr/local/data/kafka-logs-1
#kafka连接zookeeper的地址,要把多个kafka实例组成集群,对应连接的zookeeper必须相同
zookeeper.connect=192.168.31.162:2181目前我们已经有一个zookeeper实例和一个broker实例在运行了,现在只需要在启动2个broker实例即可:
bin/kafka-server-start.sh -daemon config/server-1.properties
bin/kafka-server-start.sh -daemon config/server-2.properties查看zookeeper确认集群节点是否都注册成功:

3.2 Docker Kafka集群
Docker 搭建 Kafka 集群,我们只需启动三个容器。
docker run -d --name kafka0 -p 9092:9092 --link zookeeper:zookeeper \
-v /usr/kafka/config/server.properties:/config/server.properties \
-e KAFKA_BROKER_ID=0 \
--env KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181 \
--env KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.31.193:9092 \
--env KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \
--env KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR=1 \
-t bitnami/kafkadocker run -d --name kafka1 -p 9093:9093 --link zookeeper:zookeeper \
-v /usr/kafka/config/server.properties:/config/server.properties \
-e KAFKA_BROKER_ID=1 \
--env KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181 \
--env KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.31.193:9093 \
--env KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9093 \
--env KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR=1 \
-t bitnami/kafkadocker run -d --name kafka1 -p 9094:9094 --link zookeeper:zookeeper \
-v /usr/kafka/config/server.properties:/config/server.properties \
-e KAFKA_BROKER_ID=2 \
--env KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181 \
--env KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.31.193:9094 \
--env KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9094 \
--env KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR=1 \
-t bitnami/kafka